一个Like例子
Select id,name,hobby from customer where hobby like '%文学%'
语句查询“喜欢文学的所有客户”。执行计划如图:

可见对 customer 表进行全表扫描。当数据到千万级,查询性能可想而知。
实上,已经在 HOBBY 字段上建立了索引,为什么 Oracle 不采用这个索引来提高查询效率呢?原因就在于like '%文学%'操作中的前面一个%号。因为B*树索引是个排序的东西,如果你需要匹配查询包含“文学”二字的所有内容,那Oracle就无序可循,没必要使用这个索引了。
进一步观察 customer 表的内容如下:
SQL> Select id,name,hobby from customer;
ID NAME HOBBY
---------- -------------------- ------------------------------
1 张三 文学,艺术,电影
2 李四 运动,文学,电影
3 王五 登山,旅游,文学,艺术
… …
把客户所有的爱好都塞在一个字段 HOBBY 中了,所以查询条件只能写成like'%文学%'。问题根本原因是该表的逻辑设计不符合规范化设计理论,从而导致了全表扫描。
规范化设计
数据库规范化设计定义
以下是维基百科中关于数据库规范化设计的经典定义:
数据库规范化,又称数据库或资料库正规化、标准化,是数据库设计中的一系列原理和技术,以减少数据库中数据冗余,增进数据的一致性。关系模型的发明者埃德加·科德最早提出这一概念,并于19世纪70年代初定义了第一范式、第二范式和第三范式的概念,还与Raymond F.Boyce于1974年共同定义了BC范式。
以下是 Oracle 公司对第一范式、第二范式和第三范式的经典定义:
First normal form (1NF): All attributes must be single-valued.
- 第一范式(1NF)。所有属性必须是单值的,或者说是原子化(Primitive)的、不可分割的。
Second normal form (2NF): An attribute must be dependent upon its entity’s unique identifier.
- 第二范式(2NF)。所有属性必须依赖于该实体的唯一标识属性,也就是说每个实体应该有唯一标识属性。
Third normal form (3NF): No non-UID attribute can be dependent on another non-UID attribute.
- 第三范式(3NF)。没有一个非唯一标识属性依赖于另一个非唯一标识属性,也就是说实体中不存在传递的依赖关系。就是指表中的所有数据元素不但要能惟一地被主关键字所标识,而且它们之间还必须相互独立,不存在其他的函数关系
不符合规范化设计的若干案例
1.违反第一范式的例子
显然,上述案例就违反了第一范式。因为 HOBBY 字段不是单值的,包含了文学、艺术、电影等多个值,因此也不是原子化的,是可以分割的。
2.违反第二范式的例子
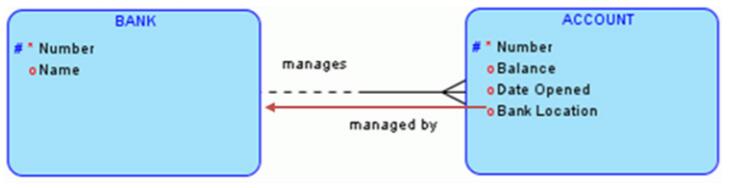
上述为银行表(BANK)和账户表(ACCOUNT)的设计,二者为一对多关系。即一个银行包含多个账户,而一个账户只属于一个银行。该设计违反了第二范式,因为ACCOUNT表中的Bank Location字段并不依赖于该表的主键Number字段,而是依赖于BANK表的主键Number字段。正确设计是将BankLocation字段移到BANK表。
3.违反第三范式的例子

上述订单表(ORDER)的设计违反了第三范式。因为数目(Quantity)和价格(Price)字段依赖于订单号(Order ID)和产品号(Line Item ID)组成的组合字段,而 ORDER 表的主键是 Order ID,也就是说该表存在传递的依赖关系。
正确的设计是新建一张订单详情表(ORDER ITEM),二者为一对多关系,而 ORDER ITEM表的主键为 Order ID 和 Line Item ID,这样 Quantity 和 Price 就依赖于 ORDER ITEM 表的主键 Order ID 和 Line Item ID 了。
回到案例
回到上述案例,看如何进行数据库设计的优化和应用优化。
即保持原来的客户表(CUSTOMER),但去掉爱好(HOBBY)字段,同时增加爱好代码表(HOBBY)用于保存所有爱好信息,以及描述客户-爱好关系的 CUST_HOBBY 表。CUSTOMER 表和 HOBBY 表形成 n:m 的关系,即每个客户可能有多个爱好,每个爱好可能为多个客户所具有。其中, CUST_HOBBY 表的主键为客户编号(C_ID)和爱好编号(H_ID)所形成的组合字段。
这样,每个字段都是不可分解的(1NF),每个表的字段都依赖于其主键(2NF),每个表也没有传递依赖关系的存在(3NF)。这就是符合第三范式的设计。
规范化设计的好处
目前普遍采用的数据库技术包括Oracle、DB2、SQL Server等都是典型的关系型数据库。所谓关系型数据库就是基于关系代数理论,依据规范化设计原则,将现实世界中的事物按实体、关系、属性等要素进行划分和描述,并通过结构化查询语言(Structured QueryLanguage,SQL)进行数据的存储、访问、操作和管理的技术。在关系模型中,最重要的设计原则就是规范化设计。规范化设计的好处如下:
1.提高访问效率
通过上述案例的详细介绍可以看到,通过规范化设计和合理的索引设计,保证了查询效率的提高。
2.降低数据冗余
在上述案例中,最初的设计不遵循第一范式,这样,“文学”一词在多条记录中会重复出现,导致了数据出现冗余。
3.保证数据一致性
在上述案例中,多条记录出现“文学”一词。如果不小心录成了“文字”,就成了不同的内容,利用like'%文学%'将查不出“文学”。这就是数据不一致性。
4.易扩展性和伸缩性
逻辑设计来源于具体的应用需求,但应尽可能建立一个与应用无关的逻辑模型,这样使得业务的变化对数据模型的影响最小,避免出现大规模的数据库结构重组,从而保证灵活适应应用变化的易扩展性和伸缩性。
非规范化设计
什么叫非规范化设计?非规范化设计就是当运用其他优化手段,例如索引策略等,已经很难达到理想的性能状态时,通过降低数据库规范化设计程度,特别是通过增加数据库冗余的方式来提高性能的一种策略。关于非规范化设计, Oracle 公司给出如下建议:
- 先从规范化设计开始;
- 将非规范化设计作为性能优化的最后招数;
- 当性能指标满足之后,不要再做进一步的非规范化设计工作;
- 将整个非规范化过程记录在案,包括非规范化的模型设计,以及应用程序进行的相应变更。
例如:
订单主表(ORDERS)和订单详表(ORDER_ITEMS),二者为1:N关系。如果在ORDERS表中增加一个ORDER_TOTAL字段,用于保存某份订单的总金额。这样,在需要频繁查询订单总金额的情况下,就只需要查询ORDERS一张表就可以了。
这种技术的优点是:只需访问导出或汇总数据,无须访问明细表,也无须进行复杂的计算。但缺点是:当明细数据发生变化时,需要重新计算导出或汇总数据,不仅导致正常交易性能受影响,而且应用复杂性增加。同时,这种设计违反了第二范式,即ORDER_TOTAL字段并不依赖于ORDERS表的主键ORDER_ID字段,这种情况下有可能导致数据不一致性。
原文地址:https://www.sunansheng.com/blog/20180530/oracle-nf.html

